リライトRubyで情報収集(スクレイピング)
一度書いて公開して一日にして消してしまったので書く気力が下がっていますのでポイントをまとめて書こうと思います
スクレイピングとは→クローラーやスパイダーとも呼ばれるネットで情報を集める技術
それをプログラムを組んでやろうというのが今回の試み
まず、動機となったサイトがこちらフォロワーさんのPythonによるスクレイピングをしたってブログ記事→こちら
なんとPythonを初めて触って1時間でできたらしい!!
PythonじゃなくてもRubyを知るために良いかも!ということでチャレンジ
Pythonみたいにライブラリーであるgemを活用してスクレイピングを行う
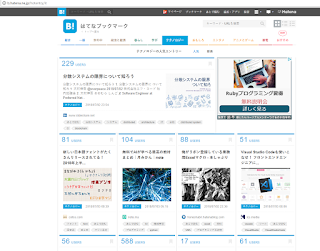
今回対象にしたのははてなブックマークのページ
http://b.hatena.ne.jp/hotentry/it
使用するgem は open-uri と nokogiri
open-uriはもともと入っているっぽい
nokogiriはRailsが入ってたら一緒に入っている
入ってない方は gem install nokogiri で入れよう!
それで今回ポテパンさんの記事を参考にしてコードを書いたが
User-Agent という落とし罠にハマった
どうやらWebページによってはOSやブラウザ情報を提出しないと開けなくて503エラーではじかれるらしい
できたコード
ということでopen の中に User-Agent項目を作りパス
あとはCSSプロパティの選択(割とややこしい)
HTMLソース情報を読み取り選択するのだけれど
doc.css() みたいに空にすると全部みれるよ!
ul li ul li で試した結果
ページ下部のデータが取得....狙っていたものと違う


色々試した結果h3要素があっていたらしく取得成功しました!

 割と簡単にできますが正直ニュースみたい程度では必要ないかと思います
割と簡単にできますが正直ニュースみたい程度では必要ないかと思います
これをうまく使ってツイッターでいいねした画像を自動保存したり
もしくは動画サイトで動画を取得したりできるようなのでそっちを活用しましょう!
また、自作ブログのトップページに注目ニュースやお天気情報などとして表示するのも良いかも!!
スクレイピングとは→クローラーやスパイダーとも呼ばれるネットで情報を集める技術
それをプログラムを組んでやろうというのが今回の試み
まず、動機となったサイトがこちらフォロワーさんのPythonによるスクレイピングをしたってブログ記事→こちら
なんとPythonを初めて触って1時間でできたらしい!!
PythonじゃなくてもRubyを知るために良いかも!ということでチャレンジ
Pythonみたいにライブラリーであるgemを活用してスクレイピングを行う
今回対象にしたのははてなブックマークのページ
http://b.hatena.ne.jp/hotentry/it

使用するgem は open-uri と nokogiri
open-uriはもともと入っているっぽい
nokogiriはRailsが入ってたら一緒に入っている
入ってない方は gem install nokogiri で入れよう!
それで今回ポテパンさんの記事を参考にしてコードを書いたが
User-Agent という落とし罠にハマった
どうやらWebページによってはOSやブラウザ情報を提出しないと開けなくて503エラーではじかれるらしい
require 'nokogiri'
require 'open-uri'
# Fetch and parse HTML document
doc = Nokogiri::HTML(open('http://b.hatena.ne.jp/hotentry/it', 'User-Agent' => 'curl/7.47.0'))
doc.css("h3").each do |link|
puts link.content
end
できたコード
ということでopen の中に User-Agent項目を作りパス
あとはCSSプロパティの選択(割とややこしい)
HTMLソース情報を読み取り選択するのだけれど
doc.css() みたいに空にすると全部みれるよ!
ul li ul li で試した結果
ページ下部のデータが取得....狙っていたものと違う


色々試した結果h3要素があっていたらしく取得成功しました!


これをうまく使ってツイッターでいいねした画像を自動保存したり
もしくは動画サイトで動画を取得したりできるようなのでそっちを活用しましょう!
また、自作ブログのトップページに注目ニュースやお天気情報などとして表示するのも良いかも!!
コメント
コメントを投稿